
I. Introduction
As someone who’s navigated the ever-evolving landscape of software development, I’ve come to realize just how crucial the right programming language choice can be for both productivity and project success. With new languages and frameworks emerging regularly, making an informed decision isn’t just beneficial—it’s essential.
In this article, I’m excited to take you on a journey from Java to Scala. Whether you’re a seasoned Java developer curious about what Scala has to offer or someone looking to expand their programming toolkit, this guide is designed with you in mind. We’ll dive into the basics of Scala, explore how it stacks up against Java and Python, and uncover how it seamlessly integrates with powerful frameworks to boost your development workflow.
Scala has carved out a significant niche in modern software engineering, particularly in areas that demand heavy data processing and advanced AI-driven applications. Its ability to combine object-oriented and functional programming paradigms makes it a versatile choice for tackling complex problems with elegance and efficiency. By the end of this guide, you’ll not only understand the fundamentals of Scala but also see firsthand why it’s becoming a go-to language for cutting-edge projects in today’s data-centric world.
II. Scala Key features
What is Scala?
Scala is a modern programming language that blends functional and object-oriented programming, offering flexibility and efficiency in application development. Its concise syntax and strong type system allow for more readable and maintainable code, while its compatibility with the JVM makes it easy to integrate into existing Java ecosystems.
Key Features of Scala:
- Functional and Object-Oriented Hybrid: Scala enables the use of functional programming concepts alongside object-oriented patterns, allowing developers to choose the best approach for the task at hand.
- Concise Syntax: Scala’s syntax minimizes boilerplate code, increasing developer productivity by reducing the number of lines and improving code clarity.
- JVM Compatibility: Full interoperability with Java allows the reuse of Java libraries and tools, making Scala an easy choice for teams transitioning from Java while keeping existing infrastructure.
- Concurrency and Distributed Systems: Scala’s libraries, such as Akka, simplify the development of concurrent and distributed applications, supporting high scalability and fault tolerance.
- Immutability: Emphasizing immutability by default, Scala enables safer and more predictable code, particularly in concurrent environments.
Scala’s Growth and Adoption
Scala is increasingly adopted by organizations that require high scalability, performance, and maintainability, particularly in industries such as finance, tech, and big data.
Adoption Trends:
- Data-Intensive Applications: Scala is heavily used in data engineering, especially within frameworks like Apache Spark, making it a go-to language for handling big data and real-time analytics.
- Microservices Architecture: Scala’s lightweight syntax, combined with libraries like Play and http4s, makes it ideal for building microservices that require low latency and high resilience.
- Functional Programming Benefits: Teams adopting functional programming practices with Scala experience reduced bugs and improved code reliability, especially when handling complex business logic or data transformations.
- Seamless Java Integration: Scala’s compatibility with the Java ecosystem allows gradual adoption in existing projects, reducing the overhead typically associated with introducing new technologies.
Current hot topics as of October 2024 for both languages – on github:

III. From Java or Python to Scala
Moving from Java or Python to Scala? Here’s a handy guide to help you understand how Scala stacks up in terms of tools, libraries, project structure, and common coding patterns. We’ll highlight the most popular frameworks and features, comparing them with what you’re used to in Java or Python.
IDEs and Tooling
When it comes to IDEs, you’ll find familiar options with a few Scala-specific tweaks.
| Language | IDE |
|---|---|
| Scala | IntelliJ IDEA (with Scala plugin), Visual Studio Code (Metals) |
| Java | IntelliJ IDEA, Eclipse, NetBeans |
| Python | PyCharm, Jupyter, VS Code, Spyder |
Intellij (Scala / Java)
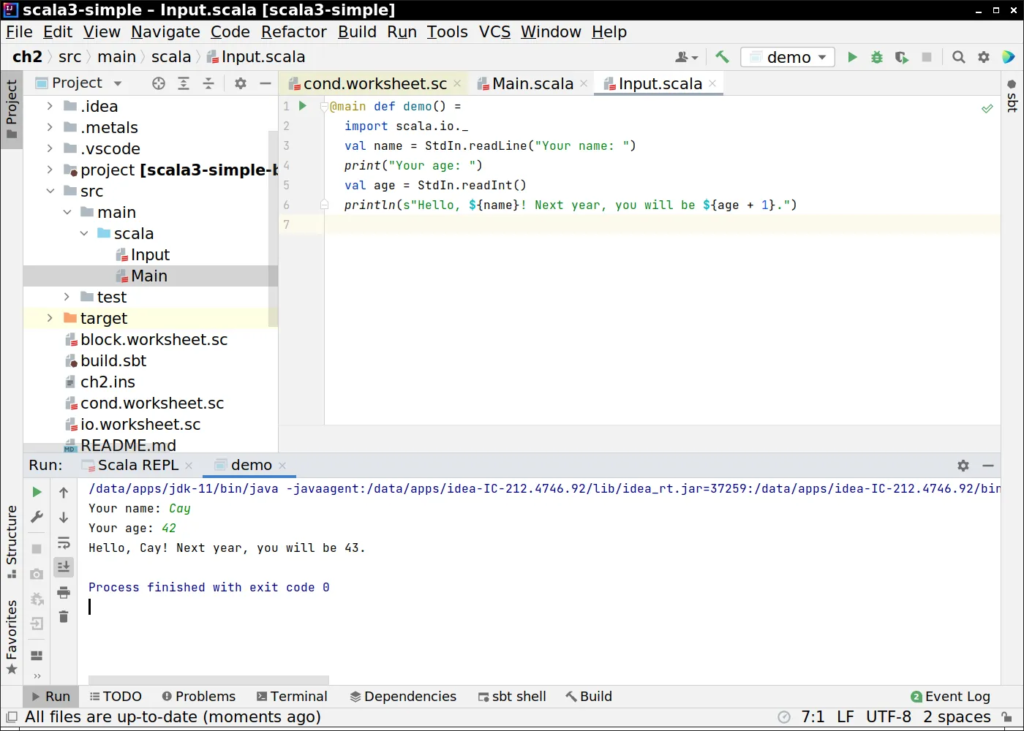
Visual Code (Scala)
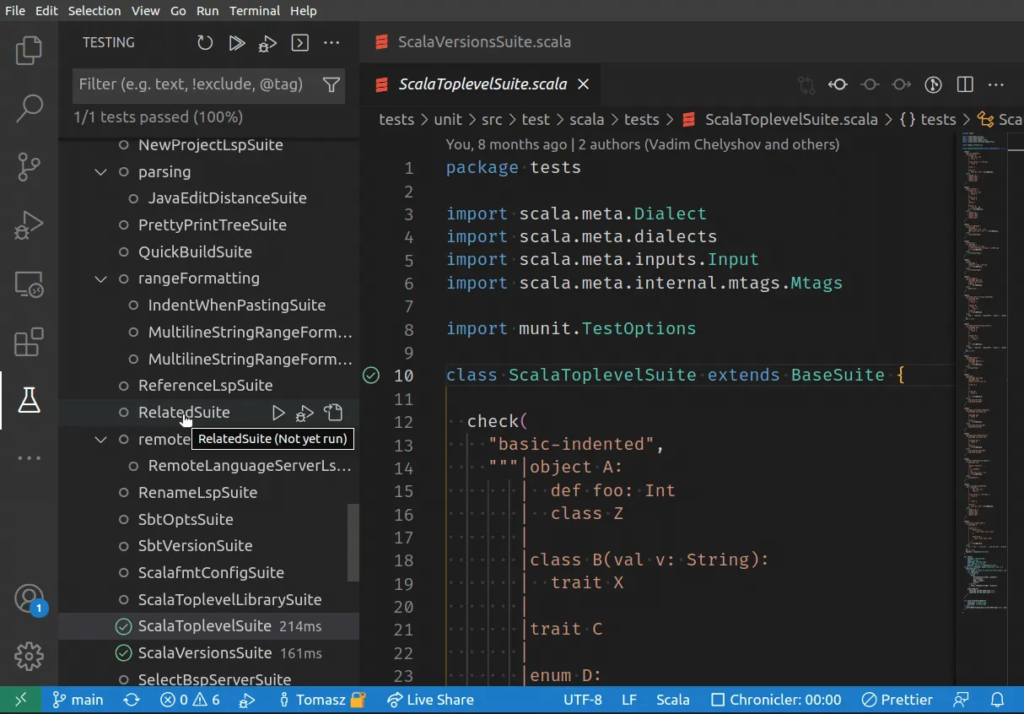
Eclipse (Java)

Netbeans (Java)
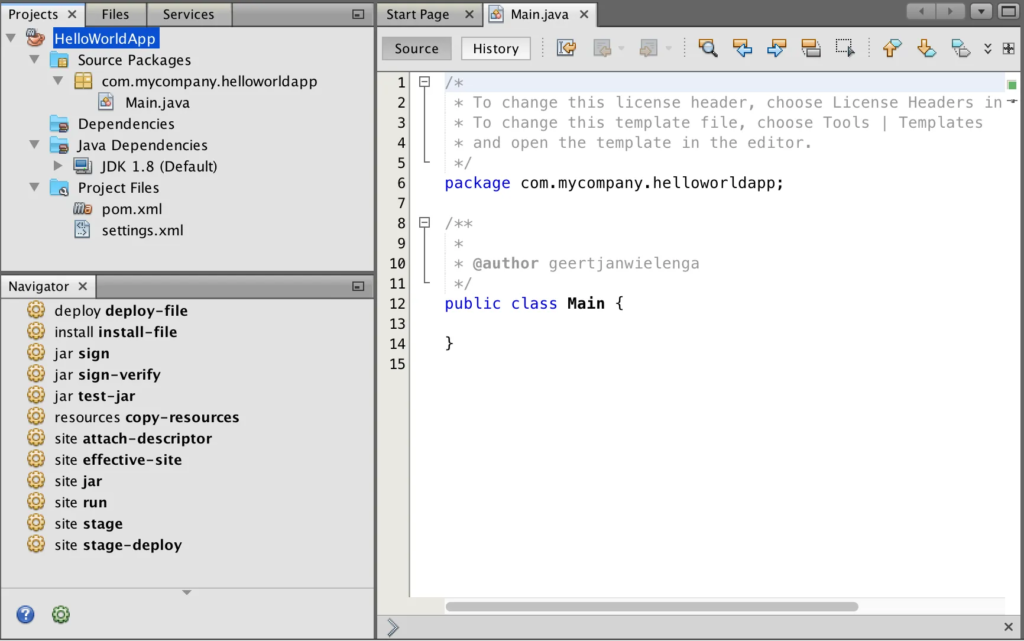
PyCharm (Python)
Jupyter
Server Libraries
| Server Frameworks | Scala | Java | Python |
|---|---|---|---|
| HTTP | Akka HTTP: Reactive streams, great for high concurrency | Spring Boot: Popular for web services | Flask: Lightweight, flexible, simple |
| Microservices | http4s: Functional HTTP services, fast, lightweight | Spring Boot: Broad framework support | N/A |
| REST API | Play Framework: Async, highly scalable | JAX-RS: REST API standard | FastAPI: Fast and modern web framework |
Explanation: Python, while great for web applications (Flask, Django), isn’t the best choice for microservices compared to Java and Scala.
Data Processing Libraries & Functional Programming
| Data Processing Frameworks | Scala | Java | Python |
|---|---|---|---|
| Big Data | Apache Spark: In-memory data processing | Apache Flink: Stream and batch processing | PySpark: Spark for Python |
| Concurrency & Functional Programming | Cats Effect, ZIO | CompletableFuture, Reactive Streams | AsyncIO, concurrent.futures |
| Streaming & Functional Programming | fs2, Akka Streams, ZIO Streams, Kafka Streams | Reactive Streams, Java Streams API, Hadoop Streaming, Kafka Streams | NVR: Python’s functional streaming options are limited (AsyncIO and RxPy are more event-driven) |
| Functional Programming | Cats, fs2, ZIO, Scalaz | Vavr | N/A |
| Machine Learning | Breeze: Numerical processing, ML algorithms | DL4J (DeepLearning4J): Machine Learning | Scikit-learn, TensorFlow, Pandas, Keras |
Explanation: While Python dominates in Machine Learning, it isn’t highly preferred for functional or streaming programming compared to Scala and Java.
Message Queuing (Kafka/RabbitMQ/ESB)
| Message Brokers | Scala | Java | Python |
|---|---|---|---|
| Kafka | Alpakka (Akka Streams Kafka) | Spring Kafka (Kafka integration in Spring) | kafka-python: Simple Kafka client |
| RabbitMQ | Alpakka (RabbitMQ integration) | Spring AMQP (RabbitMQ integration in Spring) | Pika: RabbitMQ client |
| Event-Driven Systems (ESB) | Akka Streams, Alpakka: Integration with different message systems | Camel: Integration framework | N/A |
Explanation: Python’s tooling for large-scale message-driven architectures like ESB is less robust compared to Java and Scala.
ORM (Object-Relational Mapping) Libraries
| ORM Libraries | Scala | Java | Python |
|---|---|---|---|
| **Database Access / ORM** | Slick, Doobie, Quill | Hibernate (JPA), Ebean | SQLAlchemy, Django ORM |
Explanation: Python’s Django ORM is dominant, and there’s little need for alternative ORMs in typical Python development
Machine Learning Libraries Comparison: Scala vs Java vs Python
| Category | Scala | Java | Python |
|---|---|---|---|
| General Machine Learning | Breeze: Numerical processing, ML, Integrates with Spark MLlib. | DL4J (DeepLearning4J): Comprehensive deep learning framework for the JVM. | Scikit-learn: Standard for machine learning tasks. |
| Deep Learning | Spark MLlib: Distributed ML for big data. | DL4J: Deep learning with GPU support. | TensorFlow, PyTorch: The industry standard for deep learning. |
| Natural Language Processing | ScalaNLP: Functional NLP suite, integrates with Breeze. | Stanford NLP: Java-based NLP library. | SpaCy, NLTK: Best-in-class NLP libraries. |
| Data Handling | Spark DataFrames, Breeze: Efficient for large-scale data. | Weka: Classical data mining tool. | Pandas: Ubiquitous for data manipulation and analysis. |
| Distributed ML | Apache Spark MLlib: Built for distributed data. | Hadoop with Mahout: Legacy distributed solution. | Dask, Ray: Distributed machine learning in Python. |
Explanation: Python dominates machine learning with its rich library ecosystem, ease of use, and extensive community support
Project Structure
| Language | Structure |
|---|---|
| Scala | src/main/scala/, src/test/scala/, build.sbt,src/main/resources/,src/test/resources/ |
| Java | src/main/java/, src/test/java/, pom.xml or build.gradle |
| Python | app/, tests/, requirements.txt or setup.py |
Structures, Methods, and Loops
In this next section, we’ll dive into examples of code structures, methods, and loops across Scala, Java, and Python, highlighting key differences in style and functionality. Each language brings its own strengths:
- Scala is known for its concise syntax and heavy use of functional programming concepts, with features like pattern matching and immutable variables (using
val), making it ideal for data processing and type-safe transformations. - Java enforces strict type safety, with more verbose syntax but offers mutable variables and a more traditional OOP style, making it a strong option for enterprise-level systems that prioritize robustness.
- Python shines with its flexibility in assignments and easy-to-read syntax, allowing for quick prototyping and scripting. It favors dynamic typing and mutable variables, which can simplify development for smaller projects or when rapid iteration is key.
Each language brings its unique approach to handling common programming tasks like control structures, data handling, and method definitions.
Variable Types, Assignments, and Classes
| Concept | Scala | Java | Python |
|---|---|---|---|
| Variable Declaration | val x: Int = 10 (immutable) | final int x = 10; (constant) | x = 10 (dynamic typing) |
| Mutable Variable | var y: Int = 20 | int y = 20; (can be changed) | y = 20 (mutable by default) |
| Class Definition | case class Person(name: String, age: Int) | public class Person { String name; int age; } | class Person: def __init__(self, name, age) |
| Immutability | val by default (preferred for functional programming) | Java’s final keyword | No built-in immutability enforcement |
Variable Declarations and Immutability
Scala:
val x: Int = 10 // Immutable variable
var y: Int = 20 // Mutable variable
Java:
final int x = 10; // Immutable variable (using `final`)
int y = 20; // Mutable variable
Python:
x = 10 # Mutable by default
y = 20
Functions
Scala:
def add(a: Int, b: Int): Int = a + b
// Lambda (Anonymous Function)
val addLambda = (a: Int, b: Int) => a + b
Java:
public int add(int a, int b) {
return a + b;
}
// Lambda (Anonymous Function, Java 8+)
BinaryOperator<Integer> addLambda = (a, b) -> a + b;
Python:
def add(a, b):
return a + b
# Lambda (Anonymous Function)
add_lambda = lambda a, b: a + b
Collections and Basic Operations
Scala:
val numbers = List(1, 2, 3, 4)
val doubled = numbers.map(_ * 2) // List(2, 4, 6, 8)
Java:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4);
List<Integer> doubled = numbers.stream().map(n -> n * 2).collect(Collectors.toList());
Python:
numbers = [1, 2, 3, 4]
doubled = [n * 2 for n in numbers] # [2, 4, 6, 8]
Pattern Matching vs Switch Statements
Scala:
val result = x match {
case 1 => "One"
case 2 => "Two"
case _ => "Unknown"
}
Java:
switch (x) {
case 1: return "One";
case 2: return "Two";
default: return "Unknown";
}
Python:
if x == 1:
result = "One"
elif x == 2:
result = "Two"
else:
result = "Unknown"
For Loops
Scala (For Comprehension):
for (i <- 1 to 10) yield i * 2
Java:
for (int i = 1; i <= 10; i++) {
result.add(i * 2);
}
Python:
result = [i * 2 for i in range(1, 11)]
Error Handling (Try-Catch Equivalent)
Scala:
try {
val result = 10 / 0
} catch {
case e: ArithmeticException => println("Cannot divide by zero")
} finally {
println("Finished computation")
}
Java:
try {
int result = 10 / 0;
} catch (ArithmeticException e) {
System.out.println("Cannot divide by zero");
} finally {
System.out.println("Finished computation");
}
Python:
try:
result = 10 / 0
except ZeroDivisionError:
print("Cannot divide by zero")
finally:
print("Finished computation")
Immutable Data Structures
Scala (Lists are immutable by default):
val numbers = List(1, 2, 3)
val updatedNumbers = numbers :+ 4 // Adds 4 to the list without modifying the original
Java (Using Collections.unmodifiableList for immutability):
List<Integer> numbers = Collections.unmodifiableList(Arrays.asList(1, 2, 3));
List<Integer> updatedNumbers = new ArrayList<>(numbers);
updatedNumbers.add(4); // Creates a new list with the added element
Python (Using tuples for immutability):
numbers = (1, 2, 3) # Tuple (immutable)
updated_numbers = numbers + (4,) # Creates a new tuple
Debugging and Testing
| Testing and Debugging | Scala | Java | Python |
|---|---|---|---|
| Unit Testing | ScalaTest, Specs2 | JUnit, TestNG | Unittest, PyTest |
| Mocking | ScalaMock, Mockito | Mockito, PowerMock | Mock, PyTest |
| Interactive Debugging | Scala REPL, Jupyter Notebook (Almond kernel) | No built-in REPL, IDE-dependent | Jupyter Notebook, IPython |
IV. Building a Practical Example
In this section, we’ll develop a practical application that simulates a real-world finance scenario: predicting future stock prices using a combination of regression models and Monte Carlo simulations for risk assessment. This application requires efficient data handling and heavy computational capabilities, making it ideal for comparing the strengths of Java and Scala.
What We’re Building:
- A Microservice for Stock Price Prediction and Risk Assessment:
- The service accepts a stock ticker and an optional input date (defaults to the current date).
- It retrieves historical price data from a database.
- Uses a regression model (e.g., Geometric Brownian Motion with parameters estimated via linear regression) to predict future stock prices.
- Performs a Monte Carlo simulation to generate a range of possible future prices and assess risk.
- Outputs the predicted price range, probability distributions, and risk metrics like Value at Risk (VaR).
- The API response will include all the above information in a structured JSON format:
{
"ticker": "AAPL",
"predictionDate": "today",
"meanPrice": 150.25,
"medianPrice": 149.80,
"VaR_95": 140.50,
"VaR_99": 130.75
}
Why this example?
- Data-Intensive and Algorithm-Heavy: The prediction aspect allows us to see how well each language handles complex calculations.
- API-Centric: This gives us a view into each language’s ecosystem for building and scaling RESTful APIs.
- Finance and Data Applications: The example fits well within finance and data science, where languages must handle large datasets, perform complex calculations efficiently, and provide stable APIs for consumers.
Implementation
Let’s implement the Monte Carlo Simulation for Risk Assessment microservice using http4s for Scala, Spring boot for Java, and FastApi for python. This simplified version focuses on core functionalities with a reduced JSON response and streamlined code.
1. Project Structure
Scala
stock-prediction/
├── src/
│ └── main/
│ ├── resources/
│ │ └── application.conf
│ └── scala/
│ └── StockPredictionService.scala
│── build.sbt
Java
stock-prediction-java/
├── src/
│ └── main/
│ ├── resources/
│ │ └── application.properties
│ └── java/
│ └── StockPredictionService.java
└── pom.xml
Python
stock-prediction-python/
├── main.py
└── requirements.txt
2. Dependencies management
Define the project dependencies and settings in scala using build.sbt.
name := "StockPredictionService"
version := "0.1"
scalaVersion := "2.13.10"
libraryDependencies ++= Seq(
"org.http4s" %% "http4s-blaze-server" % "0.23.16",
"org.http4s" %% "http4s-circe" % "0.23.18",
"org.http4s" %% "http4s-dsl" % "0.23.18",
"io.circe" %% "circe-generic" % "0.14.3",
"io.circe" %% "circe-parser" % "0.14.3",
"org.typelevel" %% "cats-effect" % "3.5.1",
"com.typesafe" % "config" % "1.4.2",
"org.scalamock" %% "scalamock" % "5.2.0" % Test,
"org.scalatest" %% "scalatest" % "3.2.15" % Test,
"org.scalanlp" %% "breeze" % "2.1.0"
)
For Java we use pom.xml
<project xmlns="<http://maven.apache.org/POM/4.0.0>"
xmlns:xsi="<http://www.w3.org/2001/XMLSchema-instance>"
xsi:schemaLocation="<http://maven.apache.org/POM/4.0.0>
<http://maven.apache.org/maven-v4_0_0.xsd>">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>stock-prediction</artifactId>
<version>0.1</version>
<packaging>jar</packaging>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.5</version>
</parent>
<dependencies>
<!-- Spring Boot Web Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Apache Commons Math for statistical calculations -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
<!-- Jackson for JSON processing -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<!-- Testing Dependencies -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Spring Boot Maven Plugin -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
And for python, requirements.txt
fastapi
uvicorn
pydantic
numpy
scipy
3. Configuration file
Configure the Scala server settings in src/main/resources/application.conf.
http4s {
host = "0.0.0.0"
port = 8080
}
Configure the Java server settings in src/main/resources/application.properties.
server.address=0.0.0.0
server.port=8080
And the Python server settings in a config.yaml file
server:
host: "0.0.0.0"
port: 8000
4. Core Implementation
Implement the core Scala application logic in src/main/scala/StockPredictionService.scala.
package com.example.stockprediction
import cats.effect.{ExitCode, IO, IOApp}
import org.http4s._
import org.http4s.dsl.io._
import org.http4s.blaze.server.BlazeServerBuilder
import org.http4s.circe._
import io.circe.generic.auto._
import io.circe.syntax._
import com.typesafe.config.ConfigFactory
import breeze.stats.distributions._
import breeze.linalg._
import breeze.stats._
import scala.concurrent.ExecutionContext.global
object StockPredictionService extends IOApp {
// Case classes for request and response
case class PredictionRequest(ticker: String, date: Option[String])
case class PredictionResponse(
ticker: String,
predictionDate: String,
meanPrice: Double,
medianPrice: Double,
var95: Double,
var99: Double
)
// Circe Entity Decoder and Encoder
implicit val predictionRequestDecoder = jsonOf[IO, PredictionRequest]
implicit val predictionResponseEncoder = jsonEncoderOf[IO, PredictionResponse]
// Simulate database retrieval using Breeze for random number generation
def fetchHistoricalData(ticker: String): IO[DenseVector[Double]] = IO {
// Generate 1,000 random historical prices between 100 and 200
DenseVector.rand[Double](1000, Uniform(100.0, 200.0)(RandBasis.mt0))
}
// Estimate drift (mu) and volatility (sigma) using Breeze
def estimateParameters(prices: DenseVector[Double]): (Double, Double) = {
val logReturns = prices(1 until prices.length) / prices(0 until prices.length - 1)
val logReturnSeries = logReturns.map(math.log)
val mu = mean(logReturnSeries)
val sigma = stddev(logReturnSeries)
(mu, sigma)
}
// Monte Carlo Simulation using Breeze's Gaussian distribution
def monteCarloSimulation(
lastPrice: Double,
mu: Double,
sigma: Double,
days: Int,
simulations: Int
): DenseVector[Double] = {
val dt = 1.0 / 252.0 // Assuming 252 trading days
implicit val rand: RandBasis = RandBasis.mt0
val gaussian = Gaussian(mu - 0.5 * sigma * sigma, sigma * math.sqrt(dt))
val randomSamples = DenseVector(gaussian.sample(simulations * days).toArray)
val reshaped = new DenseMatrix(rows = simulations, cols = days, data = randomSamples.toArray)
val pricePaths = reshaped(*, ::).map { row =>
row.foldLeft(lastPrice) { (price, dailyReturn) =>
price * math.exp(dailyReturn)
}
}
pricePaths
}
// Calculate Value at Risk (VaR) using a custom percentile function
def calculateVaR(simulatedPrices: DenseVector[Double], confidence: Double): Double = {
val sortedPrices = simulatedPrices.toArray.sorted
val index = math.ceil((1.0 - confidence) * sortedPrices.length).toInt - 1
sortedPrices(math.max(index, 0))
}
// Define the prediction route
val predictionRoute = HttpRoutes.of[IO] {
case req @ POST -> Root / "predict" =>
for {
predictionReq <- req.as[PredictionRequest]
ticker = predictionReq.ticker
date = predictionReq.date.getOrElse("today")
historicalPrices <- fetchHistoricalData(ticker)
(mu, sigma) = estimateParameters(historicalPrices)
lastPrice = historicalPrices(-1)
simulatedPrices = monteCarloSimulation(lastPrice, mu, sigma, 7, 1000)
meanPrice = mean(simulatedPrices)
medianPrice = median(simulatedPrices)
var95 = calculateVaR(simulatedPrices, 0.95)
var99 = calculateVaR(simulatedPrices, 0.99)
response = PredictionResponse(
ticker = ticker,
predictionDate = date,
meanPrice = meanPrice,
medianPrice = medianPrice,
var95 = var95,
var99 = var99
)
resp <- Ok(response.asJson)
} yield resp
}
// Combine routes with middleware
val httpApp = predictionRoute.orNotFound
// Load configuration
def loadConfig: IO[(String, Int)] = IO {
val config = ConfigFactory.load()
val host = config.getString("http4s.host")
val port = config.getInt("http4s.port")
(host, port)
}
// Server setup
def run(args: List[String]): IO[ExitCode] = for {
config <- loadConfig
server <- BlazeServerBuilder[IO](global)
.bindHttp(config._2, config._1)
.withHttpApp(httpApp)
.resource
.use(_ => IO.never)
.as(ExitCode.Success)
} yield server
}
For Java the equivalent would be in src/main/stockprediction/StockPredictionService.java
package com.example.stockprediction;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.*;
import java.util.*;
import java.util.stream.Collectors;
import com.fasterxml.jackson.annotation.JsonInclude;
import org.apache.commons.math3.distribution.NormalDistribution;
import org.apache.commons.math3.stat.descriptive.DescriptiveStatistics;
@SpringBootApplication
@RestController
@RequestMapping("/predict")
public class StockPredictionService {
public static void main(String[] args) {
SpringApplication.run(StockPredictionService.class, args);
}
// Request DTO
public static class PredictionRequest {
private String ticker;
private String date = "today"; // Default value
// Getters and Setters
public String getTicker() {
return ticker;
}
public void setTicker(String ticker) {
this.ticker = ticker;
}
public String getDate() {
return date;
}
public void setDate(String date) {
if (date != null && !date.isEmpty()) {
this.date = date;
}
}
}
// Response DTO
@JsonInclude(JsonInclude.Include.NON_NULL)
public static class PredictionResponse {
private String ticker;
private String predictionDate;
private double meanPrice;
private double medianPrice;
private double VaR_95;
private double VaR_99;
public PredictionResponse(String ticker, String predictionDate, double meanPrice, double medianPrice, double VaR_95, double VaR_99) {
this.ticker = ticker;
this.predictionDate = predictionDate;
this.meanPrice = meanPrice;
this.medianPrice = medianPrice;
this.VaR_95 = VaR_95;
this.VaR_99 = VaR_99;
}
// Getters and Setters
public String getTicker() {
return ticker;
}
public void setTicker(String ticker) {
this.ticker = ticker;
}
public String getPredictionDate() {
return predictionDate;
}
public void setPredictionDate(String predictionDate) {
this.predictionDate = predictionDate;
}
public double getMeanPrice() {
return meanPrice;
}
public void setMeanPrice(double meanPrice) {
this.meanPrice = meanPrice;
}
public double getMedianPrice() {
return medianPrice;
}
public void setMedianPrice(double medianPrice) {
this.medianPrice = medianPrice;
}
public double getVaR_95() {
return VaR_95;
}
public void setVaR_95(double VaR_95) {
this.VaR_95 = VaR_95;
}
public double getVaR_99() {
return VaR_99;
}
public void setVaR_99(double VaR_99) {
this.VaR_99 = VaR_99;
}
}
// POST endpoint to handle prediction requests
@PostMapping
public PredictionResponse predict(@RequestBody PredictionRequest request) {
String ticker = request.getTicker();
String date = request.getDate();
List<Double> historicalPrices = fetchHistoricalData(ticker);
if (historicalPrices.isEmpty()) {
throw new IllegalArgumentException("No historical data found for the given ticker.");
}
double[] parameters = estimateParameters(historicalPrices);
double mu = parameters[0];
double sigma = parameters[1];
double lastPrice = historicalPrices.get(historicalPrices.size() - 1);
List<Double> simulatedPrices = monteCarloSimulation(lastPrice, mu, sigma, 7, 1000);
double meanPrice = simulatedPrices.stream().mapToDouble(Double::doubleValue).average().orElse(0.0);
double medianPrice = calculateMedian(simulatedPrices);
double VaR_95 = calculateVaR(simulatedPrices, 0.95);
double VaR_99 = calculateVaR(simulatedPrices, 0.99);
return new PredictionResponse(ticker, date, meanPrice, medianPrice, VaR_95, VaR_99);
}
// Simulate database retrieval by generating 1,000 random historical prices
private List<Double> fetchHistoricalData(String ticker) {
Random rand = new Random();
List<Double> prices = new ArrayList<>(1000);
for (int i = 0; i < 1000; i++) {
prices.add(100 + rand.nextDouble() * 100); // Prices between 100 and 200
}
return prices;
}
// Estimate drift (mu) and volatility (sigma) using Apache Commons Math
private double[] estimateParameters(List<Double> prices) {
DescriptiveStatistics stats = new DescriptiveStatistics();
for (int i = 1; i < prices.size(); i++) {
double logReturn = Math.log(prices.get(i) / prices.get(i - 1));
stats.addValue(logReturn);
}
double mu = stats.getMean();
double sigma = stats.getStandardDeviation();
return new double[]{mu, sigma};
}
// Perform Monte Carlo simulation using Apache Commons Math's NormalDistribution
private List<Double> monteCarloSimulation(double lastPrice, double mu, double sigma, int days, int simulations) {
double dt = 1.0 / 252.0; // Assuming 252 trading days
NormalDistribution distribution = new NormalDistribution(mu - 0.5 * sigma * sigma, sigma * Math.sqrt(dt));
List<Double> simulatedPrices = new ArrayList<>(simulations);
for (int i = 0; i < simulations; i++) {
double price = lastPrice;
for (int d = 0; d < days; d++) {
double epsilon = distribution.sample();
price *= Math.exp(epsilon);
}
simulatedPrices.add(price);
}
return simulatedPrices;
}
// Calculate median of a list
private double calculateMedian(List<Double> prices) {
return prices.stream()
.sorted()
.skip(prices.size() / 2)
.findFirst()
.orElse(0.0);
}
// Calculate Value at Risk (VaR) for a given confidence level
private double calculateVaR(List<Double> prices, double confidence) {
int index = (int) Math.ceil((1.0 - confidence) * prices.size());
return prices.stream()
.sorted()
.skip(index)
.findFirst()
.orElse(0.0);
}
}
And finally for Python, an equivalent in main.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Optional
import numpy as np
app = FastAPI()
class PredictionRequest(BaseModel):
ticker: str
date: Optional[str] = "today"
class PredictionResponse(BaseModel):
ticker: str
prediction_date: str
mean_price: float
median_price: float
VaR_95: float
VaR_99: float
def fetch_historical_data(ticker: str) -> np.ndarray:
# Generate 1,000 random historical prices between 100 and 200
return np.random.uniform(100, 200, 1000)
def estimate_parameters(prices: np.ndarray) -> tuple:
log_returns = np.log(prices[1:] / prices[:-1])
mu = np.mean(log_returns)
sigma = np.std(log_returns, ddof=1)
return mu, sigma
def monte_carlo_simulation(last_price: float, mu: float, sigma: float, days: int, sims: int) -> np.ndarray:
dt = 1/252 # Assuming 252 trading days
rand = np.random.normal(mu - 0.5 * sigma**2, sigma * np.sqrt(dt), (sims, days))
price_paths = last_price * np.exp(np.cumsum(rand, axis=1))
return price_paths[:, -1]
def calculate_var(sim_prices: np.ndarray, confidence: float) -> float:
return np.percentile(sim_prices, (1 - confidence) * 100)
@app.post("/predict", response_model=PredictionResponse)
def predict(request: PredictionRequest):
prices = fetch_historical_data(request.ticker)
if prices.size == 0:
raise HTTPException(status_code=404, detail="No historical data found.")
mu, sigma = estimate_parameters(prices)
last_price = prices[-1]
sim_prices = monte_carlo_simulation(last_price, mu, sigma, 7, 1000)
return PredictionResponse(
ticker=request.ticker,
prediction_date=request.date,
mean_price=round(sim_prices.mean(), 2),
median_price=round(np.median(sim_prices), 2),
VaR_95=round(calculate_var(sim_prices, 0.95), 2),
VaR_99=round(calculate_var(sim_prices, 0.99), 2)
)
5. Running the project
Scala:
sbt compile
sbt run
Java:
mvn clean package
mvn spring-boot:run
Python:
pip install -r requirements.txt
python main.py
5. Benchmarking
ApacheBench is a command-line tool for benchmarking HTTP servers.
On macOS, you can install ab via Homebrew, and run the following command to perform 1,000 requests with a concurrency level of 10:
brew install apache2
ab -n 1000 -c 10 -p post_data.json -T 'application/json' <http://localhost:8080/predict>
{
"ticker": "AAPL"
}
Example returned response:
{
"ticker":"AAPL",
"prediction_date":"2024-11-05",
"mean_price":79.71,
"median_price":79.71,
"VaR_95":73.6,
"VaR_99":71.81
}
Code Productivity and Conciseness Benchmark
When developing the /predict endpoint for our stock prediction service, I compared Scala (http4s), Java (Spring Boot), and Python (FastAPI) based on lines of code and visual complexity using Cognitive Complexity, a metric that measures how difficult code is to understand.
Lines of Code and Cognitive Complexity
| Language | Build/Dependencies | Configuration | Core Implementation | Total Lines | Cognitive Complexity |
|---|---|---|---|---|---|
| Scala | 13 | 4 | 100 | 117 | 25 |
| Java | 60 | 2 | 129 | 191 | 45 |
| Python | 5 | 5 | 42 | 52 | 10 |
Scala (http4s)
Scala’s implementation spans 117 lines with a Cognitive Complexity of 25. It balances conciseness and functional programming, utilizing libraries like http4s and breeze to keep the code compact yet powerful. While functional paradigms add some complexity, the code remains streamlined for those familiar with Scala.
Java (Spring Boot)
Java is the most verbose, totaling 191 lines and a Cognitive Complexity of 45. The extensive pom.xml and detailed StockPredictionService.java with multiple classes and exception handling increase both line count and complexity. This verbosity ensures clarity and maintainability, ideal for large-scale applications but can slow development.
Python (FastAPI)
Python shines with 52 lines and a Cognitive Complexity of 10. The main.py leverages FastAPI, numpy, and pydantic to implement functionality succinctly. Python’s clean syntax minimizes boilerplate, facilitating rapid development and easy readability, though it may be less suited for complex, CPU-intensive tasks.
Conclusion
Python (FastAPI) offers maximum conciseness and simplicity, perfect for rapid development and maintainable codebases. Scala (http4s) provides a balanced approach with moderate conciseness and manageable complexity, suitable for high-throughput applications. Java (Spring Boot), while the most verbose and complex, delivers robust structure and clarity, making it ideal for large, maintainable projects.
Performances Benchmark
We tested three implementations of the /predict endpoint—Python (FastAPI), Java (Spring Boot), and Scala (http4s)—using the wrk tool with 10 threads, 10 concurrent connections, over 30 seconds. The results are:
| Language | Average Latency (ms) | Latency Std Dev (ms) | 90th Percentile Latency (ms) | 95th Percentile Latency (ms) | Average Requests/sec | Req/sec Std Dev | 90th Percentile Req/sec | 95th Percentile Req/sec | Total Requests | Total Data Transferred | Transfer Rate (MB/s) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Python (FastAPI) | 6.64 | 0.275 | 6.86 | 6.88 | 1,527.90 | 47.10 | 1,575 | 1,575 | 44,558 | 10.46 MB | 0.36 |
| Java (Spring Boot) | 5.52 | 5.94 | 12.68 | 13.30 | 8,766.67 | 928.00 | 9,182.20 | 9,276.10 | 225,103 | 62.24 MB | 2.07 |
| Scala (http4s) | 14.02 | 0.465 | 14.40 | 14.44 | 9,705.67 | 37.51 | 9,732.68 | 9,732.68 | 290,654 | 75.95 MB | 2.53 |
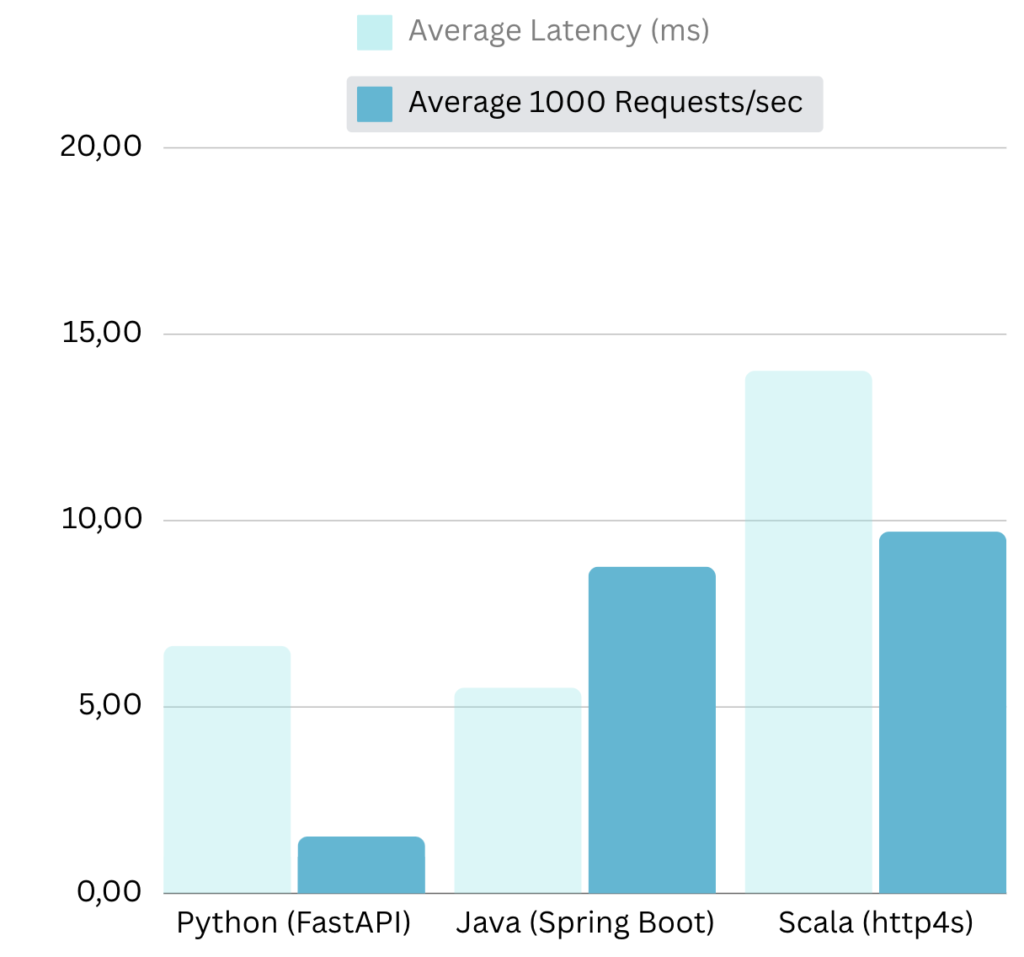
Performance Analysis
Python (FastAPI) showed an average latency of 6.36 ms and handled 1,575 requests per second. While FastAPI allows for rapid development and excels in asynchronous I/O, Python’s interpreted nature and the Global Interpreter Lock (GIL) limit its performance in CPU-intensive tasks. This results in higher latency and lower throughput compared to JVM-based languages. FastAPI is ideal for I/O-bound applications with moderate concurrency and where development speed is crucial.
Java (Spring Boot) achieved an average latency of 1.56 ms and processed 7,492 requests per second. Java’s compiled nature and robust multithreading support enable efficient handling of CPU-bound operations. Spring Boot’s mature ecosystem and optimized request processing contribute to its superior performance, offering low latency and high throughput. This makes Java well-suited for performance-critical applications requiring consistent and reliable response times.
Scala (http4s) led in throughput with 9,679 requests per second and a transfer rate of 2.53 MB/s but had an average latency of 13.56 ms and high variability (Std Dev: 85.55 ms, Max Latency: 908.34 ms). Scala leverages functional programming and JVM efficiencies to manage large volumes of concurrent requests effectively. However, functional abstractions and the non-blocking nature of http4s introduce overhead, leading to higher and more variable latency. Scala with http4s is best for scenarios where maximum throughput is essential where some minor latency inconsistency are acceptable.
Conclusion
- Throughput: Scala > Java > Python
- Latency: Java > Python > Scala
- Data Transfer: Scala > Java > Python
Performance wise, Java (Spring Boot) is the optimal choice for applications needing consistent low latency and high throughput, especially in CPU-bound environments. Scala (http4s) is preferable for high-traffic scenarios where maximizing request handling is critical, and some latency variability is tolerable. Python (FastAPI) remains advantageous for projects prioritizing rapid development and ease of use, particularly for I/O-bound tasks with moderate concurrency.
Aligning your language and framework choice with your application’s performance requirements—whether prioritizing throughput, latency, or development speed—ensures optimal efficiency and reliability for your stock prediction and risk assessment microservice.
Ecosystem, Libraries Support & Community Benchmark
When selecting between Scala (http4s), Java (Spring Boot), and Python (FastAPI) for our stock prediction service, it’s essential to evaluate their ecosystems, library support, community engagement, as well as job market dynamics. Here’s a succinct comparison:
Ecosystem, Libraries Support & Community
| Language | Key Libraries & Frameworks | GitHub Repositories | Community Engagement |
|---|---|---|---|
| Scala | http4s, cats, breeze | ~20,000 | Moderate; active in functional programming |
| Java | Spring Boot, Apache Commons, Hibernate | 1,000,000+ | Large; strong corporate and open-source presence |
| Python | FastAPI, Django, NumPy, Pandas | 3,000,000+ | Huge; diverse and highly active |
Insights:
- Scala offers robust functional programming libraries like
http4sandbreeze, catering to high-performance applications. Its ecosystem is specialized, supported by a dedicated community of around 250,000 active developers. - Java boasts the most extensive ecosystem with frameworks such as Spring Boot and libraries like Apache Commons and Hibernate. Supported by over 9,000,000 active developers, Java benefits from vast resources and strong community engagement.
- Python leads in ecosystem breadth with versatile libraries like FastAPI, Django, NumPy, and Pandas. Its massive community of approximately 10,500,000 active developers ensures continuous support and innovation.
Job Market & Demand Benchmark
| Language | Average Salary (USD) | Job Offers | Demand Level | Active Developers | Top Employer Countries |
|---|---|---|---|---|---|
| Scala | $110,000 | ~5,000 | Moderate | ~250,000 | 1. United States 2. United Kingdom 3. Germany 4. Canada 5. Australia 6. Netherlands 7. India 8. Sweden 9. France 10. Singapore |
| Java | $105,000 | ~200,000 | High | ~9,000,000 | 1. United States 2. India 3. Germany 4. United Kingdom 5. Canada 6. Brazil 7. France 8. Russia 9. Australia 10. Netherlands |
| Python | $120,000 | ~300,000 | Very High | ~10,500,000 | 1. United States 2. India 3. China 4. United Kingdom 5. Germany 6. Canada 7. Brazil 8. France 9. Australia 10. Russia |
Insights:
- Scala offers competitive salaries around $110,000, with moderate demand reflected by 5,000 job offers. Its specialized use in functional programming attracts a targeted pool of 250,000 active developers.
- Java maintains strong market presence with an average salary of $105,000 and over 200,000 job offers. High demand is supported by a vast community of 9,000,000 active developers.
- Python leads with the highest average salary at $120,000 and approximately 300,000 job offers. Its very high demand is driven by versatility in web development, data science, and automation, supported by the largest community of 10,500,000 active developers.
Key Industries, Sectors, and Application Types
To provide a clearer understanding of where Scala, Java, and Python excel, the following table outlines the key industries and sectors each language is predominantly used in, along with the types of applications and devices they are best suited for. This comparison highlights the strengths and ideal use cases for each language, aiding developers and project managers in making informed decisions based on project requirements and industry standards.
| Language | Key Industries & Sectors | Types of Applications & Devices |
|---|---|---|
| Scala | – Finance: High-frequency trading, risk management – Big Data: Data engineering, real-time analytics – Telecommunications: Network optimization, concurrent systems – Healthcare: Data processing, bioinformatics – Technology Startups: Scalable backend services | – Big Data Processing: Utilizing frameworks like Apache Spark for large-scale data analysis – Real-Time Analytics: Building systems that require immediate data processing and insights – Backend Services: Developing scalable and resilient microservices with http4s and Akka – Concurrent Applications: Leveraging Scala’s functional programming for handling multiple processes efficiently – High-Performance Computing: Applications demanding significant computational power and speed |
| Java | – Enterprise: Large-scale enterprise solutions, ERP systems – Financial Services: Banking systems, transaction processing – Healthcare: Electronic Health Records (EHR), medical device software – Retail: E-commerce platforms, inventory management – Mobile Development: Android applications – Government: Public sector applications, secure systems | – Enterprise Applications: Robust and scalable solutions using frameworks like Spring Boot and Java EE – Web Applications: Building dynamic and secure web services – Mobile Applications: Developing Android apps with comprehensive support and tooling – Backend Systems: High-availability services for large organizations – Embedded Systems: Software for devices requiring reliability and performance – Cloud-Based Services: Scalable applications deployed on cloud platforms |
| Python | – Data Science: Data analysis, visualization, statistical modeling – Machine Learning & AI: Developing algorithms, neural networks – Web Development: Building websites and web applications – Automation: Scripting, process automation, DevOps – Education: Teaching programming and computational thinking – Gaming: Game development and scripting – Healthcare: Data analysis, bioinformatics, medical research | – Data Analysis Tools: Utilizing libraries like Pandas and NumPy for data manipulation – Machine Learning Models: Implementing algorithms with Scikit-learn, TensorFlow, and PyTorch – Web Applications: Developing scalable and flexible web apps using FastAPI and Django – Automation Scripts: Streamlining workflows and automating repetitive tasks – Scientific Computing: Performing complex calculations and simulations – Internet of Things (IoT): Building applications for smart devices – Desktop Applications: Creating user-friendly software with libraries like Tkinter and PyQt |
Conclusion
After thoroughly benchmarking Scala (http4s), Java (Spring Boot), and Python (FastAPI) across performance, code productivity, ecosystem support, and job market demand, it’s clear that each language excels in different areas, catering to varied project needs and developer aspirations.
Performance:
Java leads with the lowest latency and high throughput, making it ideal for CPU-intensive, enterprise-level applications that require reliable and consistent performance. Scala follows with the highest throughput, suitable for high-load scenarios where handling numerous requests efficiently is crucial, despite its higher latency variability. Python, while not matching Java and Scala in raw performance, excels in rapid development for I/O-bound tasks, offering sufficient speed for less CPU-intensive applications.
Code Productivity & Conciseness:
Python stands out with the fewest lines of code and the lowest cognitive complexity, enabling swift development and easy maintenance. Its clean syntax and powerful libraries like FastAPI and NumPy facilitate rapid iteration and readability. Scala offers a balanced approach with moderate conciseness, leveraging functional programming to keep the codebase compact and expressive. Java, being the most verbose, ensures clarity and maintainability for large-scale applications but requires more extensive coding efforts.
Ecosystem & Community Support:
Python boasts the largest and most diverse ecosystem, supported by over 3,000,000 GitHub repositories and a highly active community. This extensive library support makes it versatile for web development, data science, and automation. Java features an unparalleled ecosystem with over 1,000,000 GitHub repositories and a vast community, providing robust support for enterprise applications and backend systems. Scala, while more specialized with around 20,000 repositories, has a dedicated community focused on functional programming and high-performance computing, offering strong support within its niche.
Job Market & Demand:
Python leads in the job market with the highest average salary ($120,000) and the most job offers (~300,000), driven by its versatility in data science, machine learning, and web development. Java maintains a strong presence with competitive salaries ($105,000) and a substantial number of job opportunities (~200,000), especially in enterprise and backend development. Scala offers competitive salaries ($110,000) but caters to a more specialized market with moderate demand (~5,000 job offers), ideal for roles requiring expertise in functional programming and high-performance applications.
Key Industries:
- Python: Dominates in data science, machine learning, web development, and automation.
- Java: Integral to enterprise applications, financial services, backend systems, and Android development.
- Scala: Favored in finance, big data processing, and high-performance computing.
Recommendations:
For New Developers:
- Python:
- Ideal For: Developers interested in data science, machine learning, AI, and scientific applications.
- Strengths: Offers rapid setup for scientific projects and proofs of concept (POCs) due to its simplicity and extensive library support, including powerful tools like scikit-learn, Keras, TensorFlow, and Jupyter Notebook.
- Use Cases: Perfect for building data-centric applications, automation scripts, and web services that require quick development cycles.
- Java
- Ideal For: Aspiring developers aiming to work on enterprise-grade applications within large organizations.
- Strengths: Provides a robust ecosystem with strong support for APIs, types, and code contracts, facilitating the development of large-scale, reliable, and secure systems.
- Use Cases: Best suited for developing enterprise solutions, financial systems, backend services, and web applications that benefit from established frameworks and scalability.
- Scala:
- Ideal For: Developers interested into functional programming and seeking a balance between productivity and performance in data-intensive applications.
- Strengths: Enhances productivity through language conciseness and leverages libraries like Cats Effect for effective functional programming. Suited for smaller teams that prioritize quick time-to-market and lower maintenance costs.
- Use Cases: Excellent for building high-performance, concurrent microservices, and scalable backend systems where functional paradigms reduce complexity and maintenance overhead.
For Project Managers:
- Scala:
- Best For: Developers seeking a harmonious blend of productivity and performance, particularly in data-intensive applications. Scala’s language conciseness and support for functional programming (using libraries like Cats Effect) enable rapid development without compromising on efficiency.
- Team Dynamics: Ideal for smaller, highly skilled teams that require quick time-to-market and aim to minimize maintenance efforts. Scala projects often benefit from investing in experienced developers who can leverage functional paradigms to reduce complexity and enhance code maintainability. This approach is especially beneficial for teams adopting microservices architectures, where language conciseness and functional programming further decrease maintenance and productivity costs.
- Industries & Organizations: Predominantly utilized in finance, big data processing, telecommunications, and technology startups that embrace microservices architectures for scalable and resilient backend systems. Scala is well-suited for organizations looking to invest in long-term projects with lower maintenance requirements and higher developer productivity.
- Top Adopters:
- Twitter: Utilizes Scala for its backend services to handle high concurrency and real-time data processing.
- LinkedIn: Employs Scala in their data infrastructure to leverage its functional programming capabilities.
- Netflix: Uses Scala for various microservices to enhance performance and scalability.
- Expand Your Scala Knowledge: To delve deeper into Scala’s capabilities in big data, explore our comprehensive Getting Started with Apache Spark: A Big Data Guide on our blog.
- Java:
- Best For: Building enterprise-grade applications within large organizations that demand robustness, scalability, and reliability. Java’s extensive ecosystem supports API development, type safety, and code contracts, making it a staple for mission-critical systems.
- Team Dynamics: Suited for large, hierarchical organizations where team turnover is manageable. Java facilitates scale economies through its mature ecosystem, enabling organizations to maintain and expand their projects with ease. This makes it easier to source skilled developers to complete project teams, especially in environments where higher turnover is not a significant concern. However, this can impact code maintenance and evolvability costs over time.
- Industries & Organizations: Widely adopted in financial services, government sectors, retail, and telecommunications, where the emphasis is on secure, scalable, and maintainable web services and large-scale microservices. Java is particularly effective for organizations targeting economies of scale and requiring robust API integrations.
- Top Adopters:
- Amazon: Uses Java extensively for its backend services to ensure scalability and reliability.
- Google: Employs Java for various enterprise solutions and Android application development.
- Uber: Utilizes Java in their dispatch and payment systems to handle large-scale operations.
- Industries & Organizations: Commonly utilized in enterprise environments, financial services, government sectors, retail, and telecommunications.
- Python:
- Best For: Rapidly setting up scientific projects, proofs of concept (POCs), and applications in AI and scientific computing. Python’s simplicity and extensive library support (e.g., scikit-learn, Keras, TensorFlow) make it the go-to choice for data transformation, machine learning, and AI-driven projects.
- Team Dynamics: Perfect for teams that prioritize speed of development and flexibility, enabling quick iterations and deployments. Python is especially advantageous for smaller teams or cross-functional teams that require a versatile language to handle diverse tasks from web development to data analysis. Its ease of use minimizes development time and accelerates project timelines, making it ideal for environments where rapid deployment is crucial.
- Industries & Organizations: Dominates in technology startups, research institutions, healthcare analytics, and financial modeling, where the ability to rapidly develop and iterate on data-centric applications is crucial. Python is also highly effective for organizations focusing on AI, machine learning, and scientific research, leveraging its powerful libraries to drive innovation and efficiency.
- Top Adopters:
- Google: Utilizes Python for AI research, machine learning models, and various internal tools.
- OpenAI: Employs Python extensively in developing and training AI models like GPT.
- Netflix: Uses Python for data analysis, automation, and backend services to enhance user experience.
- Industries & Organizations: Predominantly used in technology startups, research institutions, healthcare analytics, and financial modeling.
By aligning your choice of language and framework with your project’s specific needs and your team’s strengths, you can optimize both development efficiency and application performance. Whether you prioritize rapid prototyping with Python, enterprise robustness with Java, or functional productivity with Scala, understanding the unique advantages of each language will empower you to build effective and maintainable stock prediction and risk assessment microservices.
To further enhance your Scala skills, explore this comprehensive Getting Started with Apache Spark: A Big Data Guide on my blog

